OpenAI Gym
강화 학습 모델을 개발하기 위한 특수한 툴킷이다.
기본적은 환경으로 막대의 균형을 잡는 문제인 CartPole과 자동차를 산 위로 이동시키는 MountainCar 등이 있다.
(손을 뻗어 벤치에 있는 물건을 집거나 미는 로봇을 훈련하고 블록, 공, 펜의 방향을 바꾸기 위한 로봇 손을 훈련하는
고급 로봇 환경도 제공)
$pip3 install gym
CartPole-v1
![Introducing CartPole-v1 - Hands-On Q-Learning with Python [Book]](resources/DD2B0E4D89E929C05198E617BB4A2802.png)
막대가 세로로 붙어 있는 카트를 수평 방향으로 움직일 수 있다.
막대의 움직임은 물리 법칙을 따른다.
강화 학습 에이전트는 막대 균형을 잡아 넘어지지 않도록 카트를 움직이는 방법을 배우는 것이 목표이다.
import gym
env=gym.make('CartPole-v1')
env.observation_space
Box(-3.4028234663852886e+38, 3.4028234663852886e+38, (4,), float32)
CarPole의 관측 공간은 (4, )이다.(4차원 공간으로 카트의 위치, 카트의 속도, 막대의 각도, 막대의 각속도)
oberservation)space는 Box 클래스의 객체로 처음 두개의 숫자는 가능한 최솟값, 최대값
env.action_space
Discrete(2)
env.reset()
array([ 0.0498444 , 0.02550881, -0.0032414 , -0.00845212])
카트의 초기 상태 리셋
초기 위치, 속도, 막대의 각도(라디안), 막대의 각속도를 나타냄
[-0.05, 0.05] 범위의 균등 분포에서 초기화
env.step(action=0)
env.step(action=1)
(array([ 0.05035458, -0.16956651, -0.00341044, 0.28320635]), 1.0, False, {})
(array([ 0.04696325, 0.02560392, 0.00225369, -0.01055026]), 1.0, False, {})
action=0은 왼쪽, action=1은 오른쪽으로 박스를 이동시킴을 나타낸다.
반환된 튜플은 네 개의 원소로 이루어져 있다.
- 새로운 상태(관측)을 위한 배열
- 보상(float 타입의 스칼라 값)
- 종료 플래그(True or False)
- 부가 정보를 담은 파이썬 딕셔너리
env.render()
각 단계가 끝나고 실행하면 시간의 흐름에 따라 막대와 카트의 움직임과 환경을 시각화할 수 있다.
막대의 각도가 수직 축으로부터 12도보다 커지거나 카트의 위치가 중앙 위치에서 2.4보다 멀어지면 에피소드가 종료된다.
정의된 보상은 카트와 막대가 정해진 범위 안에서 균형을 잡고 잇는 시간을 최대화 하는 것이다.
(보상을 최대화 하기위해서는 에피소드의 길이를 최대화해야 한다.)
GridWorld
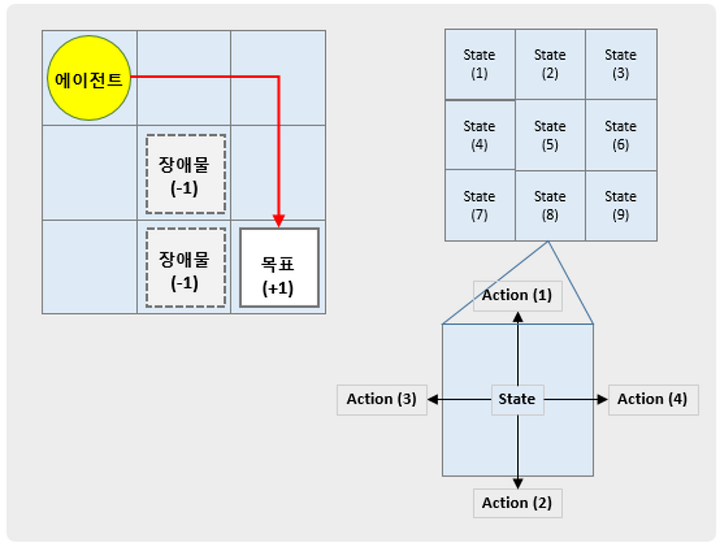
골드 상태와 함정 상태가 존재한다.
에이전트는 항상 일정한 위치에서 시작한다.(환경을 초기화 할 때만다 에이전트가 같은 위치로 되돌아간다.)
골드 상태에 도달하면 +1의 양의 보상을 함정 상태 중 하나에 도달하면 -1의 음의 보상을 받는다.